-
The Compute Arbitrage – Why the “Software-Only” Outsourcing Model Just Died

For three decades, global technology hubs built empires on human capital. The formula was simple: hire the brightest engineering minds, seat them in a modern facility with standard business laptops, and bill western clients on a predictable time-and-material (T&M) basis.
But in 2026, that traditional software-only delivery model has collided with a hard physical ceiling. Clients are no longer asking engineering partners: “Do you have the developers to write this pipeline?” They are asking: “Do you have the dedicated physical clusters to run and test our models at scale?”
The Operational Friction: The Latency and Egress Trap
When global enterprises move from AI experimentation to production-grade deployment, they encounter an architectural nightmare. Moving petabytes of sensitive, proprietary corporate data back and forth across oceans to centralized Silicon Valley hyperscalers introduces crippling latency and catastrophic data-egress bills.
Furthermore, data sovereignty laws now dictate that enterprise data cannot freely cross borders for processing. The operational demand has shifted radically: global clients are forcing IT service giants in hubs like India, Poland, and the Philippines to host, fine-tune, and run inference locally within secure, regional boundaries.
The traditional cost advantage of offshore developer salaries is being completely overshadowed by the astronomical costs of unoptimized cloud infrastructure. If an IT delivery center relies entirely on public APIs, their margins are swallowed by the platform owners.
The Framework: The 2026 Outsourcing Maturity Matrix
To survive this shift, forward-thinking IT providers are aggressively restructuring their service catalog from a labor-first mindset to an infrastructure-first reality:
- The Legacy Tier (Rapidly Commoditizing): Delivering human bodies to handle basic software maintenance, manual QA, and legacy code migration. These margins are collapsing.
- The Transition Tier (Margin Squeezed): Building wrapper applications using external, expensive public APIs. These firms are highly vulnerable to hyperscaler pricing whims and client data-leakage anxieties.
- The Sovereign Tier (The New Elite): Owning or deeply partnering with the physical localized hardware layer to run private, secure enterprise inference on-site. They sell guaranteed compute time alongside engineering expertise.
Labor arbitrage is dead; it has been replaced by compute arbitrage. If your IT delivery partner doesn’t have direct, local access to high-density hardware infrastructure, they aren’t an AI transformation partner—they are just an unpaid QA team for big tech.
-
Architecting Contextual Moats.

Beyond the Algorithm: Building the Hyper-Localized Enterprise Engine
The first two parts of this series established a brutal double reality: hardware constraints are limiting the endless expansion of raw compute power, and global AI models are fundamentally blind to the implicit, non-digitized nuances of regional execution.
The corporate response to this double wall cannot be surrender, nor can it be to simply throw more capital at Western API providers. The solution requires a fundamental architectural pivot. Forward-thinking organizations must stop competing on the size of their foundational model and start competing on the depth of their proprietary context.
We are moving from the era of model-centric AI to context-centric AI. The ultimate enterprise asset is no longer the raw processing engine; it is the localized data moat built around it.
Building this contextual moat requires three structural transformations:
- The Extraction of Grassroots Knowledge: Organizations must design deliberate, structured pipelines to capture the implicit knowledge that lives entirely in the field. This means digitizing the unstructured operational wisdom of local distributors, regional sales leaders, and field engineers. If a critical market variable—like informal credit behavior or hyper-local infrastructure vulnerabilities—only exists inside a human head, it must be systematically captured, cleaned, and vectorized into an enterprise knowledge base.
- Architecting Small, Specialized Networks: Instead of routing every complex enterprise query to a monolithic, multi-billion-parameter global model that burns massive compute and hallucinates stability, architectures must shift toward ensembles of Small Language Models (SLMs). These lightweight models are highly optimized, exceptionally fast, cost-efficient, and trained explicitly on localized datasets. They don’t need to know the entire history of the world; they just need to master the exact operational mechanics of their target domain.
- Local Context Injection (RAG at the Edge): Foundational global models can still be used as general translation or reasoning layers, but they must be strictly governed by localized Retrieval-Augmented Generation (RAG) frameworks. Before an algorithm makes a predictive inventory decision or drafts a B2B sales communication, it must be forcefully injected with the real-time, ground-level constraints of that specific regional market.
By building proprietary data pipelines that prioritize deep local context over raw, brute-force processing muscle, enterprises can insulate themselves from global infrastructure shortages while achieving unprecedented operational precision.
The businesses that dominate the next decade will not be those with the biggest data centers, but those that successfully bridge the gap between global computation and hyper-local execution.
-
The Hallucination of Universality

The Cost of a Clean Dataset: Why Enterprise AI Stumbles at the Local Border
The boardrooms of the West share a dangerous consensus: that intelligence is a commodity scaling linearly with computational power. If an LLM can pass a bar exam, analyze a complex legal contract, or write functional Python script, it should easily optimize a distribution network or predict consumer behavior anywhere on the planet.
This assumption is not just wrong; it is financially hazardous.
What global AI strategies consistently miss is the difference between explicit data and implicit context. Global models are trained on the cleanly digitized, highly structured, and Western-centric open internet. They excel in environments where rules are written down, codified, and followed to the letter. But the moment you drop these multi-billion-parameter engines into a highly dynamic, hyper-fragmented ecosystem like the Indian market, the system fractures.
Consider the reality of a tier-2 or tier-3 distribution network in India. A global model looks at logistics data and assumes Western infrastructure parameters—predictable freight timelines, clear regulatory compliance structures, and formalized B2B communication.
It cannot calculate the operational gravity of localized variables:
- The informal credit networks built entirely on decades of multi-generational trust (“Kirana” dynamics) that dictate whether an order is accepted or rejected.
- The infrastructure micro-shocks—from sudden localized monsoon flooding to regional market closures—that never make it into a centralized database but live entirely inside the heads of regional on-ground distributors.
- The linguistic and cultural elasticity where a verbal “yes” or a specific phrasing in a regional market doesn’t mean a contractual commitment; it means a negotiation has officially begun.
When a global model encounters these unquantifiable realities, it does not stop and request more data. Instead, it does something far worse: it hallucinates universality. It forces the chaotic, hyper-localized operational reality into a clean, Westernized corporate template that it understands.
The result? AI-driven demand forecasting that misses inventory positions by critical margins, automated sales scripts that completely alienate long-term distributors, and strategic roadmaps built for an imaginary, perfectly organized market that does not exist on the ground.
Brute-force compute can buy processing speed, but it cannot buy cultural intelligence. Until enterprise AI architectures transition away from monolithic, top-down data structures and begin integrating localized, grassroots-level operational context, the “universal” model will remain an expensive corporate illusion.
-
The Sovereign Data Wall: The Night The Algorithms Hit the Ceiling

The Sovereign Data Wall: The Night The Algorithms Hit the Ceiling
For the last five years, the corporate mandate regarding AI has been singular: more compute, bigger datasets, and larger models. The underlying assumption was that universality (and compute power) would solve all contextual problems.
That assumption just hit a wall.
As detailed previously in our discussion on the “AI Tax,” physical compute infrastructure (GPUs, memory, power) is no longer a boundless commodity. Scarcity is the new default. But the true crunch is data. The internet has been scraped clean. The global datasets are digitized.
The easy part is over.
We are entering the era of Contextual Scarcity. The vast majority of valuable enterprise knowledge, proprietary cultural logic, and regional business practices—the subtle ‘know-how’ that actually powers an economy like India—remains analog, unstructured, or guarded behind corporate and sovereign firewalls.
This is the Sovereign Data Wall. Global models, facing a silicon squeeze and limited to Western-centric data pools, cannot simply brute-force their way through this wall. The AI model of the future cannot just predict generalities; it must operate within specific localized constraints. Organizations must pivot from managing hardware supply to cultivating proprietary contextual moats.
That is where the next decade’s competitive advantage lies.For the last five years, the corporate mandate regarding AI has been sing
-
Survival of the Optimized – Strategy in the Shortage Era

You can’t outspend a global structural shortage, so you have to out-think it. In 2026, the “AI PC” was supposed to be our savior—moving compute away from expensive clouds and onto our desks. But there’s a paradox: the hardware required to run AI locally is the very hardware that’s becoming prohibitively expensive.
The “AI PC” Paradox
To run a useful LLM locally, 16GB of RAM is no longer the “recommended” spec; it’s the bare minimum. 32GB is the new standard. As we saw in Part 1, the cost of these components is skyrocketing.
We are entering an era where the “Replacement Cycle” is dead. If you’re waiting for prices to “normalize” before refreshing your fleet, you might be waiting until 2028. By then, your competition will have already optimized around the shortage.
Three Pillars of the 2026 Strategy
- Inventory as a Financial Hedge: In a “Supercycle,” taking a bold inventory position isn’t just about supply—it’s a hedge against inflation. For those in the Stock & Sell motion, the “right” inventory is now more valuable than cash. If you have the hardware on the shelf, you own the market.
- The Shift to Edge & Hybrid AI: Instead of “brute-forcing” large models on every machine, winners are moving toward Edge AI. This means using smaller, hyper-optimized models that can run on existing hardware or specialized NPUs (Neural Processing Units), reducing the dependency on massive RAM/SSD clusters.
- Lifecycle Extension & Maintenance: If you can’t buy new, you must maintain. We are seeing a massive resurgence in component-level upgrades. Instead of replacing a $1,500 laptop, enterprises are spending $300 to max out the RAM and SSD—extending the ROI of their 2023/2024 investments.
The Conclusion
The winners of 2026 won’t be the companies with the most AI; they’ll be the ones who managed their hardware runway most effectively. The “Hardware Tax” is real, but it’s also a filter. It separates the companies that are just “chasing the hype” from the ones building a sustainable, hardware-aware AI future.
-
The Data Gravity Problem – Why SSDs are the New Gold

If RAM is the “brain” of the AI revolution, then SSDs (NAND Flash) are its nervous system. And right now, that nervous system is under cardiac arrest.
Data Gravity & the “KV Caching” Reality
AI models, especially Large Language Models (LLMs), don’t just process data once and forget it. They need a continuous “memory” of the context of a conversation. As these conversations get longer and the data gets heavier, a powerful pull—Data Gravity—occurs.
- The Problem: It is too expensive and energy-intensive to store all this heavy context in ultra-fast HBM/RAM.
- The Solution: Hyperscalers are offloading this “medium-term memory” to ultra-high-speed Enterprise SSDs.
- The Result: The rise of KV Caching (storing conversation context) has turned Enterprise SSDs into the most sought-after commodity on earth. Companies are building “All-Flash” data centers because “Just-in-Time” data retrieval is no longer optional for competitive AI.
The “Crumbs” of the Consumer Market
Just as we saw with RAM, this enterprise gold rush leaves the consumer and traditional IT markets with the leftovers. For businesses, this means the high-capacity QLC (Quad-Level Cell) SSDs you were planning to put into your workstations or standard servers are either:
- On allocation (meaning lead times of 3 to 6 months), or
- Selling at a premium of 70%+ higher than 2025 prices.
The narrative that “storage is cheap” is dead. In the age of AI, data has gravity, and that gravity is pulling the world’s highest-performing SSDs into a few select data centers, leaving the rest of the enterprise market paying the price.
The Strategic Takeaway for Leaders
- Validate Inventory: Don’t trust procurement forecasts. Confirm physical inventory before signing off on any major infrastructure project in 2026.
- Rethink Storage Architecure: Your business cannot compete if your on-premise infrastructure is bottlenecked by SATA SSDs. If you can’t afford the enterprise NAND, look at hyper-converged solutions that optimize existing storage.
-
The “AI Tax” Nobody Budgeted For.

In late 2025, every boardroom was talking about AI software. In 2026, those same boards are realizing they forgot to budget for the hardware. We are no longer in a “shortage”—we are in a Structural Supercycle. If you are trying to scale your digital infrastructure right now, you aren’t just fighting inflation; you are paying an “AI Tax” that is quietly doubling your procurement costs.
The “Cannibalization” of Silicon
The global memory market (DRAM) has hit a tipping point. For years, we relied on a steady supply of DDR4 and DDR5 for our laptops and servers. But the “AI Gold Rush” has changed the math of the factory floor.
Manufacturers like Samsung and SK Hynix are making a cold, hard business calculation: HBM over DDR.
- The Math of Sacrifice: High-Bandwidth Memory (HBM)—the fuel for AI chips—consumes nearly 3x the wafer capacity of standard RAM.
- The Result: Every time a batch of HBM is born to power a data center, the potential for thousands of consumer RAM sticks dies.
- Priority Shift: With HBM profit margins being nearly 10x higher than standard memory, the “allocation” phase has begun. If you aren’t a hyperscaler, you’re at the back of the line.
The 100% Price Jump
The numbers for Q1 2026 are staggering. Consumer RAM prices have surged by over 100%, and Gartner predicts that memory will now account for 23% of the total bill-of-materials (BOM) for a PC—up from just 16% last year.
This isn’t just about “expensive parts.” It’s about the disappearance of the entry-level segment. The sub-$500 laptop is effectively becoming extinct because the “base cost” of just putting 16GB of RAM into a machine has become a luxury.
The Strategic Takeaway
For leaders, the message is clear: Your 2024 procurement playbook is broken.
- Stop waiting for a “dip”: Capacity isn’t coming back until new “Mega-Fabs” go live in 2027 or 2028.
- Audit your lifecycle: The 3-year refresh cycle is now a financial liability.
- Inventory is Strategy: In a supercycle, “Just-in-Time” delivery is a recipe for project failure.
Conclusion: AI is often called “software that thinks,” but in 2026, it is behaving like a physical vacuum, sucking up the world’s silicon and leaving the rest of the enterprise market to pay the bill.
-
Bridging the Divide – The Strategy of ‘Contextual Intelligence’

We’ve established that the “Universal AI” model is built on Western assumptions (Part 1), and we’ve mapped the structural walls—Linguistic, Cultural, and Infrastructural—that widen the Global AI Divide (Part 2).
The question now is not if the divide exists, but how the marketing industry moves forward. We can’t simply wait for the largest tech companies to “add more data” from developing economies. The solution requires a fundamental strategic pivot.
1. The Death of One-Size-Fits-All
The era of the “global rollout” is over. The “Bharat” test proves that centralization is a defect, not a feature. The winning strategy of the next decade isn’t “Scale”; it’s Contextual Intelligence.
This means shifting from large, monolithic models to smaller, specialized models. Instead of one AI trying to understand all of India, forward-thinking brands are investing in discrete AI agents that specialize in specific regional high-context environments. An AI specialist for festive purchasing behavior in Tamil Nadu will always outperform a generalist model trying to cover the entire subcontinent.
2. Investing in ‘Last Mile’ Data
To break down the walls we identified, we have to address the data scarcity. The high-value data isn’t found in translated grammar books; it’s found in the “Last Mile” of the consumer journey.
We need to incentivize the digitization and ethical collection of low-resource linguistic data—slang, dialects, and localized idioms. When AI learns how consumers actually speak (e.g., in “Hinglish”), the Trust Gap closes. The divide is bridged not by high-tech algorithms, but by investing in the human context that the algorithm is supposed to serve.
3. The Human-as-Context-Layer
We have discussed how over-automation can lead to “Professional Atrophy.” In the marketing sphere, this is where the human skillset becomes premium.
AI should no longer be viewed as the strategist; it is the processor. The marketer’s new role is to serve as the “Context Layer.” The AI handles the 24/7 data analysis, but the human must inject the nuance of “Bharat.” The strategist provides the intuition on why a cultural moment matters, and the AI executes that vision at scale.
Conclusion The Global AI Divide isn’t a technical error; it is a mirror reflecting who we built the technology for. Bridging that divide doesn’t require us to build “smarter” machines. It requires us to build more empathetic marketing structures—where technology serves local context rather than forcing context to fit the technology.
-
The Three Walls – The Structural Divide
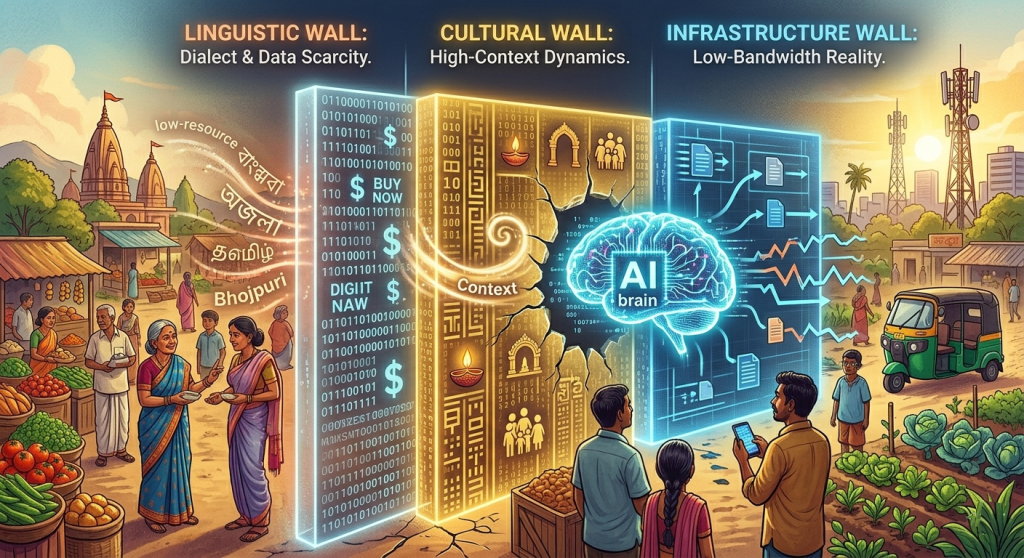
If Part 1 is about the “what,” Part 2 is about the “why.” This part focuses on three structural “Walls” that prevent global AI marketing from actually reaching the Indian heartland.
Wall 1: The Linguistic Barrier (Low-Resource Reality)
While AI is getting better at Hindi, India has thousands of dialects. The “Global AI Divide” is essentially a data scarcity problem. Because there is less digitized data for languages like Bhojpuri or Regional Marathi compared to English, the AI becomes “stupid” the further you move from the urban centers.
Wall 2: The Cultural High-Context Barrier
Western marketing is “Low-Context”—it’s direct and individualistic. Indian culture is “High-Context.” Decisions are communal. If an AI agent is programmed to push “Individualistic Empowerment” to a demographic that values “Family Security” above all else, the marketing ROI will stay at zero.
Wall 3: The Infrastructure Barrier
Often AI models are designed assuming 5G and the latest iPhone. But in developing economies, the “Divide” is literal. If your AI-driven marketing requires a heavy JavaScript load or high-bandwidth video, you have effectively “redlined” millions of potential customers who are on patchy 3G/4G networks or budget handsets.
-
The “Dictionary” Trap – Why Translation Isn’t Localization

We’ve all seen it: a global brand launches a campaign in India, and the Hindi text looks like it was run through a 2010 version of Google Translate. It’s grammatically “correct,” but it feels… off.
While going through many research papers on the Global AI Divide, I’ve found that the biggest hurdle isn’t language—it’s semiotics. Western AI models are trained on “High-Resource” datasets. They understand the dictionary definition of a word, but they are deaf to its cultural resonance.
The “Bacon” Problem If a Western AI optimizes a “Family Breakfast” campaign, it might default to imagery of eggs and bacon. In the Indian context, that’s not just a mistranslation; it’s a categorical failure. In a country where food is deeply tied to religious and communal identity, a “smart” algorithm that doesn’t understand the nuance of Satvik vs. non-vegetarian options isn’t just inefficient—it’s alienating.
The Trust Deficit When a consumer in a Tier-2 city interacts with an AI-generated ad that uses “Textbook Hindi” instead of the local dialect or “Hinglish,” a “Trust Gap” forms. The consumer realizes, “This brand doesn’t know me; they just translated a message meant for someone else.” To bridge this, we must move toward Deep Localization—where AI learns the context of the street, not just the rules of the grammar book.
-
Subscribe
Subscribed
Already have a WordPress.com account? Log in now.
